Підсистема керування збором та обробленням даних в реальному часі
1. База даних реального часу та підсистема введення/виведення
Як зазначено в попередньому розділі, центральною частиною середовища виконання SCADA-програм є база даних реального часу (БДРЧ), яка використовується для забезпечення усіх підсистем SCADA плинною інформацією про стан процесу, а також можливості втручання в процес керування. База даних реального часу – це сховище тегів (змінних), значення та атрибути яких постійно оновлюються. Таке оновлення диктується необхідністю в “свіжих” даних, щоб оператор через підсистему людино-машинного інтерфейсу мав можливість контролювати стан процесу та, за необхідності, керувати його протіканням. Окрім того, інші підсистеми (наприклад, підсистема тривог або трендів) теж потребують такого оновлення, однак, можливо, з іншою частотою (періодичністю).
У SCADA-програмах, призначених для середніх та великих систем, за роботою БДРЧ слідкує виділений програмний модуль, який будемо називати Сервером введення/виведення. Сервер введення/виведення (або аналогічна програмна частина) забезпечує, з одного боку, своєчасне оновлення плинних значень змінних із джерела даних (наприклад контролера), а з іншого – обслуговує запити на цю змінну для читання/записування з інших підсистем, які в такому зв’язку є клієнтами. При цьому Сервер введення/виведення та клієнти можуть знаходитися як на одному так і на різних комп’ютерах. Слід черговий раз відмітити, що виділення серверу введення/виведення є умовним, оскільки архітектури SCADA можуть сильно відрізнятися.
Сервери введення/виведення обмінюються з джерелами даних (наприклад контролерами) через підсистеми введення/виведення, які часто називають драйверами протоколів або просто драйверами. У цьому випадку драйвери – це програмні бібліотеки, в яких реалізовані комунікаційні протоколи. Враховуючи велику різноманітність протоколів промислових мереж, які на сьогоднішній день використовуються для з’єднання з контролерами та іншими засобами введення/виведення, наявність того чи іншого драйверу у SCADA-програмі може стати визначальним при її виборі. Наприклад, більшість SCADA-програм мають у своєму складі драйвер протоколу Modbus RTU, але мало які підтримують пропрієтарний (фірмовий) та вже застарілий протокол UNITE чи XWAY (Telemechanique). Звісно, що драйвер однієї SCADA-програми не підходить до іншої. З цих причин нерідко розробнику системи доводиться вирішувати проблему сумісності засобів SCADA/HMI з джерелами даних (контролерами). На сьогоднішній день цю проблему вдалося подолати, уніфікувавши інтерфейс підсистеми введення/виведення через технологію OPC. (Огляд деяких протоколів для підсистеми введення/виведення наведений у наступному розділі).
2. Змінні (Теги)
База даних реального часу вміщує змінні, які також називають тегами (tag), а в ряді випадків – точками (point). Слід зазначити, що в багатьох SCADA-програмах поняття “тег” та “змінна” відсутні взагалі, а побудова і функціонування серверної частини значно відрізняється від описаної в цьому посібнику. Так, у SCADA Trace Mode центральним місцем є “канали”, які вміщують всю функціональність обробки даних: від джерела до місць призначення та в зворотному напрямку. Тим не менше, нижче наводиться, певне, найбільш поширене та усереднене представлення реалізації БДРЧ. Надалі в тексті буде використовуватися поняття “тег”.
Розробник проекту створює теги відповідно до вимог його завдання. При цьому він повинен налаштувати властивості тегів для виконання потрібних операцій введення/виведення. Ці операції залежать від типу та призначення тегів і, звісно, залежать від особливостей конкретного середовища, тобто SCADA/HMI-програми.
Теги, що мають за джерело даних зовнішній пристрій (контролер) називаються тегами введення/виведення (теги I/O). Вони потребують обміну через підсистему ведення/виведення, тому мають відповідні до цього властивості та потребують налаштування обміну та перетворення (рис. 1). Для таких тегів характерні операції зчитування/записування з/в джерела даних та оброблення, таке як перевірка на діапазон та достовірність, масштабування та додаткових перетворень. Нижче наведемо орієнтовний перелік властивостей, які можуть налаштовуватися при розробленні для тегів введення/виведення:
-
ідентифікатор або ім’я тегу;
-
короткий опис (коментар);
-
тип даних (цілий, булевий, з плаваючою комою, текстовий тощо);
-
параметри налаштування вказівки на джерело даних: таких як, наприклад, мережний інтерфейс, адреса контролера, адреса змінної в контролері;
-
періодичність оновлення;
-
доступ до зміни значення: читання/записування, тільки читання;
-
параметри налаштування оброблення: масштабування, фільтрація тощо;
-
обмеження на введення;
-
одиниці виміру (наприклад “кПа”);
-
інші параметри.
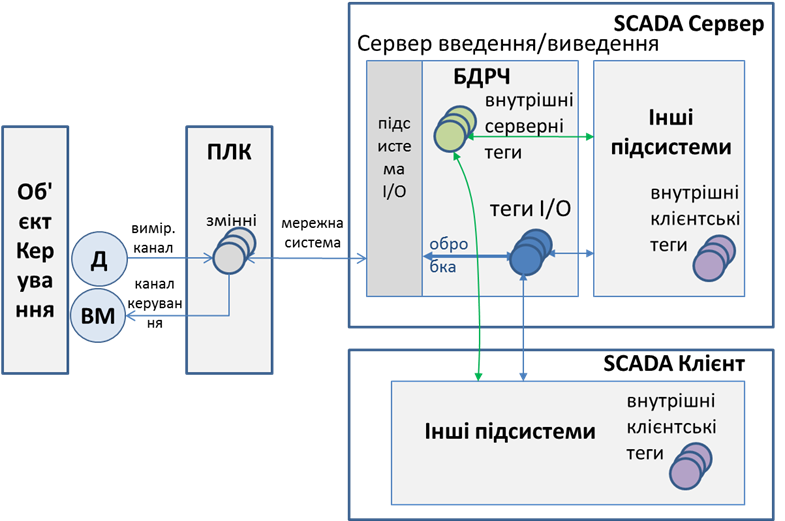
Рис.1. Оброблення тегів у контексті умовної функціональної структури SCADA
На відміну від тегів введення/виведення, внутрішні теги не потребують зв’язку з джерелом. Вони використовуються для обміну даними між підсистемами SCADA/HMI та збереження проміжних результатів. Внутрішні теги, у свою чергу, можуть бути серверними, тобто спільними для всіх підсистем та клієнтів, або клієнтськими – унікальними для кожної підсистеми та клієнта. (Додатково про принципи розділення внутрішніх тегів на клієнтські та серверні написано в підрозділі 9.1 посібника).
Окрім внутрішніх тегів, SCADA-програма додатково може надавати можливість працювати із системними тегами (наприклад, для отримання інформації про дату й час), або математичними, імітаційними чи іншими, які є специфічним для кожної SCADA-програми.
Слід зазначити, що політика ліцензування SCADA-програм, як правило, враховує кількість тегів саме введення/виведення, оскільки це опосередковано вказує на масштаби та вартість системи. Це пов’язано з тим, що чим більша вартість системи, тим більше замовник спроможній заплатити за ліцензію та більша відповідальність постачальника SCADA-програми. Тому, щоб зменшити кількість тегів введення/виведення розробники проектів для SCADA нерідко припускаються до певних прийомів. Наприклад, перед відправленням даних у контролері можна упакувати біти в цілі числа, отримуючи в результаті на кожні 16 дискретних (булевих) змінних контролера (або навіть 32) тільки один тег введення/виведення SCADA. Однак варто відмітити, що розробники середовищ SCADA можуть вираховувати такі прийоми при розрахунку ліцензійних точок.
3. Ідентифікація тегів
Кожному тегу, незалежно від його призначення, розробник проекту повинен дати унікальний у межах серверу ідентифікатор, за яким інші підсистеми зможуть звертатись до його значень. Як правило, це є ім’я тегу. У більшості випадків вимоги до формування імен схожі до вимог до змінних мов програмування:
-
використовуються тільки літери латинського алфавіту, цифри та деякі спеціальні символи;
-
не вміщують пробілів;
-
мають суттєві обмеження на кількість літер
Звісно, не обходиться без виключень з цих правил. Деякі SCADA-програми дозволяють використовувати кирилицю, а в деяких, як наприклад у SCADA zenon, змінні можуть називатися як завгодно (хоч є несуттєві обмеження на кількість літер). Не дивлячись на переваги від відсутності таких обмежень, слід обережно ставитися до використання великих імен та кирилиці. Так, ім’я “ТІ12” кирилицею і латинськими літерами виглядить однаково, хоч з точки зору програми є означеннями різних тегів, що може привести до довгого пошуку причини непрацездатності проекту SCADA/HMI.
Перед створенням тегів необхідно чітко продумати спосіб та правила формування їх імен для конкретного проекту. Це залежить від особливостей конкретної SCADA-програми, розроблювальної системи, особливостей імпорту/експорту/зв’язування з проектом контролера, а також уподобань та прийнятого стилю розробника проекту. Так, наприклад, для переробних галузей за основу може бути прийняте найменування тегів відповідно до стандарту ISA-5.1 (схеми P&ID, позначення засобів автоматизації) або його вітчизняного аналогу “ДСТУ Б А.2.4”, для диспетчеризації електричних систем - IEC 81346.
Розроблення правил найменування є важливим кроком особливо для великих проектів, де кількість тегів вимірюється сотнями і тисячами. Непродумані правила найменування або їх відсутність може значно ускладнити процес розроблення та обслуговування.
Простір імен (перелік найменувань) тегів може мати плоску (flat) або ієрархічну структуру. Плоский простір імен передбачає наявність тегів з елементарними (не складеними або не структурними) типами даних. Це стає незручним при розробленні вже при кількості тегів понад сотню. На це є декілька причин:
-
пошук тегів у просторі імен стає незручним, оскільки неможливо їх відобразити у вигляді ієрархічного дерева;
-
теги важко об’єднувати логічно;
-
проблематичною є автоматизація процесу створення анімацій.
Ці незручності частково вирішуються можливостями редакторів. Наприклад, у табличних редакторах та вікнах вибору можна вказувати фільтри для відображення (рис. 2).
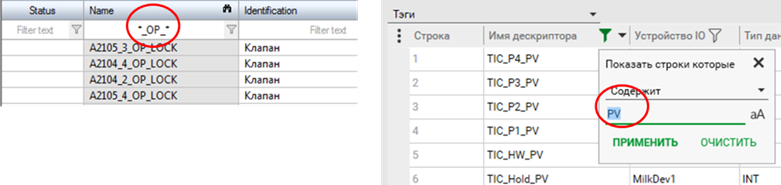
Рис. 2. Використання фільтрів у редакторах: ліворуч zenon, праворуч Citect
Класичним виходом із ситуації є використання символу “_” в якості розділового знака між рівнями ієрархії. Для кращого сприйняття імен тегів розробником у процесі створення та налагодження проекту з великою кількістю точок введення/виведення імена можуть мати псевдо-ієрархічну структуру. Наприклад, плинне значення температури (PV) з контуру (TIC100) в пастеризаторі (PAST1) цеху виробництва і пакування (VIP) може мати назву “VIP_PAST1TIC100_PV”. Псевдо-ієрархічність досягається за рахунок використання символу “” в якості розділового знака між рівнями. Хоч з точки зору SCADA/HMI таке ім’я тегу є звичайним і не відрізняється від неієрархічних, воно дозволяє простіше вирізнити тег серед інших, а в деяких випадках автоматизувати анімаційні елементи (див. підрозділ 5.5).
Ієрархічності на певному рівні можна досягти шляхом структурування типів даних для тегів. Наприклад, можна створити структурний тип даних для типової контрольованої вимірювальної змінної процесу з контролем меж, в якому будуть поля:
-
PV: для плинного значення аналогової величини;
-
HHSP: для значення уставки верхньої аварійної межі;
-
LLSP: для значення уставки нижньої аварійної межі;
-
HH: біт, що спрацьовує при перевищенні верхньої аварійної межі;
-
LL: біт, що спрацьовує при зниженні за нижню аварійну межу.
У цьому випадку, наприклад, для вимірювального параметра TT101 в базі даних тегів буде створена лише одна структурна змінна (а не п’ять), до полів якої можна буде звертатися через крапку, наприклад “TT101.PV” або “TT101.HH”. Додатковою перевагою такого підходу є зручність при створенні та модифікації проекту. Більш детально структурування змінних розглянуто у підрозділі 8.
Ім’я тегу, як правило використовується тільки для означення зв’язків у самому проекті і не видиме для оператора (користувача) системи режиму виконання. Для оператора ім’я тегу є малоінформативним і не зрозумілим, особливо якщо воно не може містити великих слів кирилицею (для місцевих операторів) та пробілів. Так, скажімо, якщо розробник проекту вирішив використовувати ідентифікацію відповідно до схеми автоматизації, то тег може мати позначення, скажімо “TT1а” для плинного значення температури, або “TV1b” для значення положення клапана. Для розробника в цьому є певний продуманий сенс, але оператор буде важко звикнути до таких найменувань. Тому, якщо на якомусь спливаючому вікні необхідно показати ідентифікатор тегу з яким робиться певна дія, або в легенді тренду вказати назву пера (кривої) замість імені тегу краще використовувати короткий опис (Description) або коментар. Ця властивість, як правило, не має таких суттєвих обмежень як ім’я тегу, і не є ідентифікуючим з точки зору SCADA, однак для оператора його можна використати саме для ідентифікації технологічного параметра, з яким він працює. У наведеному вище прикладі для тега “TT1а” можна вказати коментар “Температура на виході теплообмінника”.
З ідентифікацією тегів тісно пов’язана парадигма зв’язків між підсистемами в різних SCADA-програмах, про яку вже нагадувалося. Якщо ім’я тегу в проекті використовується в якості зв’язного тільки на етапі компіляції, то це має певні незручності при зміні назви тегу або його видаленні, що призводить до необхідності зміни в усіх місцях, де йде посилання на цей тег. В іншій парадигмі зв’язок відбувається не на рівні імен тегів, а прихованих (від розробника) ідентифікаторів, що робить зв’язок між тегами та його використанням незалежними від імені. Іншим словами, в таких системах зміна імені тегу призведе до такої ж зміни в усіх посиланнях на нього (наприклад, в анімації), що досить зручно.
4. Зв’язок із джерелом даних
Для того, щоб змінна введення/виведення зв’язалася з джерелом даних, необхідно вказати повний шлях до нього. На рис. 3 показано схему організації зв’язку між тегом введення/виведення та джерелом даних. Тег знаходиться в базі даних реального часу і за його оновленням і обробленням слідкує Сервер I/O. Нагадаємо, що виділення окремого Сервера введення/виведення є умовним, оскільки в SCADA окремо він може не виділятися, в засобах ЛМІ, як правило, БДРЧ взагалі немає. Для з’єднання із джерелом даних необхідно використати один з наявних драйверів введення/виведення (I/O). Для зв’язку з реальним фізичним інтерфейсом комп’ютера (наприклад, COM-портом, Ethernet тощо) використовуються драйвери інтерфейсів, які є системними. У ряді випадків така послідовність драйверів може мати додаткові ланки, як приклад – це використання проміжного сервера ОРС (розглянуто в наступному розділі посібника). Комунікаційний інтерфейс комп’ютера забезпечує його зв’язок з мережною системою, наприклад Ethernet, RS-232 або RS-485. У цій же мережній системі знаходиться пристрій зі змінною, яка є джерелом даних для тегу. Цей пристрій також має інтерфейс і спілкується за правилами обміну в мережі.
Таким чином, щоб сконфігурувати зв’язок тегу з джерелом даних (наприклад, зі змінною в ПЛК), необхідно вказати:
-
драйвер введення/виведення, через який відбувається зв’язок;
-
параметри комунікаційних інтерфейсів для вказаного драйвера та інших драйверів, що беруть участь в обміні;
-
адресу (адреси) пристрою в комунікаційній системі;
-
адресу (адреси) змінних у пристрої.
Цей перелік може бути доповнений у залежності від типу драйвера. (У наступному розділі посібника наведено опис декількох протоколів з точки зору їх використання в SCADA/HMI).
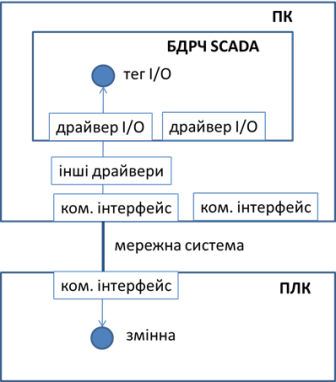
Рис. 3. Організація зв’язку тегів I/O з джерелом даних
Враховуючи, що БДРЧ повинна постійно відслідковувати плинне значення величини, його треба циклічно зчитувати із джерела даних. Як правило, це проводиться періодично з указаним періодом опитування. Цей період може зазначатися в налаштуваннях драйвера, або безпосередньо в налаштуваннях тегу.
У деяких SCADA/HMI період оновлення тегів у БДРЧ визначається автоматично під час роботи системи. Сервер введення/виведення опитується клієнтами (наприклад, HMI або підсистемою тривожної сигналізації чи підсистемою трендів), що впливає на опитування джерела даних, яке проводиться тільки за потребою. Таким чином, якщо, скажімо, певний тег використовується тільки на одній мнемосхемі і не задіяний у тривогах чи трендах, він оновлюватиметься тільки тоді, коли ця мнемосхема буде відображатися.
обмеження на введення
Значення тегів нерідко необхідно масштабувати з одиниць, що вказані в джерелі даних (контролеру) в інженерні одиниці. Це зумовлено рядом факторів, зокрема:
-
у джерелі даних (контролері) значення числових змінних знаходиться в контролерних одиницях, які для оператора не мають достатньо зрозумілого представлення;
-
одне й те саме значення необхідно представити в різних діапазонах.
Засоби SCADA/HMI в режимі виконання можуть мати вбудовані можливості зміни діапазону значення інженерних одиниць, тобто налаштувати діапазон за необхідності коригування показань датчика (градуюванні). Також деякі SCADA/HMI мають вбудовані можливості нелінійного масштабування.
Із з розвитком обчислювальних можливостей пристроїв (наприклад контролерів) функція масштабування все частіше проводиться саме на джерелі даних, тому на SCADA/HMI цим можна не користуватися.
Наведемо деякі типові підходи до організації конфігурування масштабування. Насамперед треба розділяти лінійне та нелінійне масштабування. У більшості SCADA/HMI доступне тільки лінійне масштабування, тобто перетворення вхідних сирих (RAW) контролерних одиниць в інженерні масштабовані одиниці за формулою (рис. 4):
S = k×R + Sb (1)
де S – отримуване масштабоване значення в інженерних одиницях; R – вхідне сире немасштабоване значення, Sb – зміщення; k – коефіцієнт, який дорівнює тангенсу кута нахилу прямої масштабування до осі абсцис.
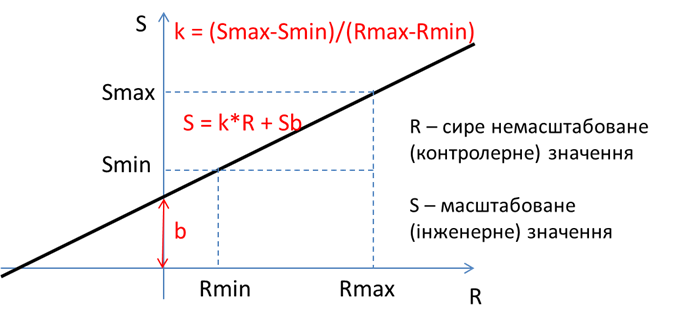
Рис.4. Лінійне масштабування
Задавання масштабування у вигляді (1) потребує від розробника додаткових розрахунків. Замість цього часто задають тільки мінімальні та максимальні межі для сирого (raw) і масштабованого (scaled) значення. На рис. 4 межі сирого значення показані, як Rmax та Rmin, а масштабованого – як Smax та Smin. Так, якщо в ПЛК значення від датчика задається в діапазоні від 0-10000 (одиниць ПЛК), а на ЛМІ воно повинно відображатися як 50.0 – 150.0 (°С), то:
Rmin = 0 (одиниць ПЛК) –> Smin = 50.0 (°С)
Rmax = 10000 (одиниць ПЛК) -> Smax = 150.0 (°С)
Неважко зробити перетворення цих меж у коефіцієнти формули (1), так як
k = (150.0°С – 50.0°С)/(0 од.ПЛК – 10000 од.ПЛК) = 0.01 °С/од.ПЛК;
b = 50.0°С (можна визначити при Rmin = 0).
Крім простоти налаштування, задавання меж має ще додаткові функції. По-перше, так може означуватися нормоване вхідне значення. Іншими словами, якщо вхідне значення з джерела даних виходить за рамки вказаного діапазону, воно вважається недостовірним. По-друге, так може виставлятися обмеження на введення. Тобто, якщо оператор (або якась підсистема) вводить значення, що виходить за межі діапазону, воно не записується в джерело даних, оскільки вважається недостовірним (помилковим). Таким чином, межі використовуються не тільки для масштабування по двох точках, а і для лімітування та сигналізації недостовірності.
Деякі SCADA/HMI дають можливість окремо задавати межі для введення. Це буває дуже доречним, оскільки операторові дозволяється вводити значення тільки з певного піддіапазону загального діапазону величини.
Крім лінійного масштабування, в деяких SCADA/HMI є можливості робити нелінійне масштабування. Способи такого масштабування дуже різноманітні. У будь-якому випадку, якщо вбудованих засобів у інструмента конфігурування немає, таке масштабування можна проводити за допомогою скриптів мовами, вбудованими в SCADA/HMI.
Зовнішній вигляд вікон конфігурування та назва параметрів залежать від конкретного типу SCADA/HMI. Як правило, призначення полів є інтуїтивно зрозумілим. Спробуйте на рис. 5 знайти поля, що відповідають за масштабування (межі сирого значення та масштабовані). Детально приклади налаштування розглянуті в кінці розділу.
6. Одиниці виміру, формат відображення
Відображення значення величини у вигляді тексту, як правило, повинно супроводжуватися одиницями вимірювання, які також називаються інженерними одиницями (engineering unit, EU). Враховуючи, що це стосується тегу, а не тільки його відображення, ці одиниці налаштовуються при конфігуруванні тегу. На рис. 5 показано приклад, де в якості одиниць вимірювання вказується °С.
Величини, що мають дробову частину, потребують означення формату відображення. Так, для відображення одиниць pH потребуються дві цифри до крапки(коми), і дві після (6.56 од. pH), а для швидкості оберту двигуна – тільки 4 цифри до коми і жодної після (1456 об/хв). Якщо неправильно налаштувати формат відображення, то в одному випадку пропадуть значимі цифри, а в іншому – будуть показуватися зайві цифри після коми, які не мають значення і тільки заважають сприйняттю інформації. Налаштування формату відображення може проводитися як на самому елементі відображення, так і у властивостях тегу.
На рис. 5 показано приклад формату “##.# EU”, в якому, в залежності від значення до коми, буде відображатися дві або менше цифр, а після коми – одна або менше. Крім того, після значення будуть відображатися інженерні одиниці (EU). Тобто при значенні 54.345678 буде відображатися 54.34 °С.

Рис. 5. Приклад налаштування тегу (SCADA Citect)
7. Властивості тегів у режимі виконання
Вище описано, які властивості є у тегів для налаштування їх оброблення і поведінки. Ці властивості умовно можна назвати властивостями режиму конфігурування. Як уже було сказано, ці властивості записуються в базу даних проекту середовища розроблення. При компілюванні вони використовуються і в середовищі виконання, однак можуть бути недоступними для відображення та/або зміни. Тому в ряді випадків частина властивостей може бути використана для додаткової анімації, а інша – ні. Наприклад, властивості масштабування можна використати для відображення користувачу дозволених меж введення.
Незалежно від того, чи є доступ у середовищі виконання до властивостей, чи немає, тег при цьому завжди характеризується мінімум трьома значеннями:
-
плинне значення (Value);
-
якість (Quality);
-
відмітка часу (Time Stamp).
Окрім плинного значення, яке характеризує числовий вимірювальний показник, для тегу характерна якість. Якщо джерело даних недоступне, то оператор повинен бути проінформований, що значення недостовірне, тобто йому немає довіри. На рис. 6 наведено приклади відображення ознаки недостовірності: в SCADA Citect замість плинного значення пишеться “BAD”, а в SCADA zenon відображаються кольорові квадратики. Слід зазначити, що якість має також різні значення, які вказують на причини. Наприклад, недостовірність може бути спричинено відсутністю зв’язку клієнта із сервером або відсутністю зв’язку сервера з джерелом даних на контролері, або навіть виходом значення за дозволений діапазон.
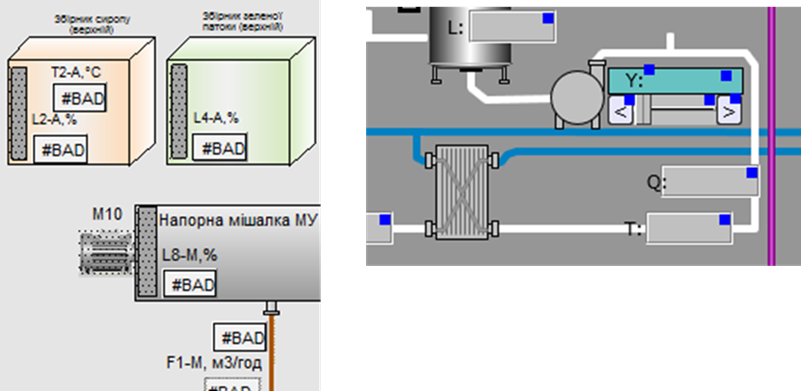
Рис. 6. Приклади вигляду відображення при відсутності зв’язку із джерелом даних: ліворуч – в Citect, праворуч – в SCADA zenon
У деяких SCADA-програмах є можливість анімувати стан тегу. На рис. 7 показано статусні біти тегу, які можна використати в анімації SCADA zenon. Так, можна змінити колір/відображення/видимість елемента залежно від біту стану SPONT (відбулася зміна значення із джерела даних) або INVALID (значення тегу недостовірне).

Рис. 7. Вибір бітів статусу тегу в анімації в SCADA zenon
Слід розуміти, що плинне значення тегу – це далеко не єдина важлива його властивість. Окрім якості, можливо, знадобиться фіксувати зміну тегу оператором або з джерела даних (контролеру), факт оновлення даних, час оновлення. Час оновлення в деяких системах є вкрай важливим фактором при фіксації події в журналах. Для відновлення послідовності подій з точністю до десятків та одиниць мілісекунд, у деяких системах SCADA передають відмітку часу разом зі значенням безпосередньо з джерела даних. Є спеціальні модулі в контролерах, що фіксують відмітку часу, та спеціальні протоколи телеметрії, які передають її разом зі значеннями даних (DNP3, IEC-60870-5).
8. Типи даних тегів
Для того щоб правильно інтерпретувати отримані з джерела дані для тегу (кількість байт, порядок біт, формат), необхідно вказати їх тип. Наприклад, для доступу до типу з плаваючою комою (32-бітного) необхідно витягувати в два рази більшу кількість байт, ніж 16-бітного цілого, а також враховувати, що формат цих 4-х байт буде інтерпретуватися відповідно до представлення числа з плаваючою комою.
Слід також розуміти, що значення на джерелі даних при перетворенні (масштабуванні) може потребувати зміни типу. Припустимо, що діапазон змінної в одиницях ПЛК 0-10000. Враховуючи що змінна в ПЛК цілочисельна, вона зберігається в змінній цілого типу (INTEGER). Однак при масштабуванні в діапазон 0.0-100.0 (%), для збереження перетвореного значення в БДРЧ знадобиться значення з плаваючою комою. Тобто типи даних для тегу в джерелі і перетвореного при масштабуванні будуть відрізнятися. У більшості випадків, перетворення типів проводиться неявно і не потребує конфігурування. У прикладі на рис. 5 вказується тільки тип даних на джерелі, хоч по факту плинне значення тегу (Value), очевидно, матиме тип з плаваючою комою (REAL).
Найменування типів в SCADA/HMI може не збігатися з найменуваннями їх у джерелі даних. Окрім того, типи з однаковою назвою в джерелі і SCADA/HMI можуть також інтерпретуватися різним чином. Тому перед означенням типу необхідно чітко розуміти співвідношення типів в SCADA/HMI і джерелі, інакше дані будуть недостатньо інтерпретовані.
Останнім часом дані в ПЛК все частіше представляються у вигляді структурних користувацьких типів (user types). Це досить зручно, бо дає можливість зберігати логічно об’єднані дані як одне ціле та зменшити кількість операцій при програмуванні та налагодженні. Структурування даних на джерелі дає змогу спростити розроблення в SCADA/HMI. Для цього в інструментальних засобах повинна бути можливість створення власного типу даних. Створення структурної змінної при цьому може зводитися тільки до означення її імені та початкової адреси. Усе інше означується типом і розраховується автоматично. На прикладі з рис. 8 структурний тип OBJ має 11 полів, які мають різний тип (BOOL, USINT, INT). При створенні змінної на базі цього типу задається тільки номер блоку даних та початкове зміщення відносно нього (у даному випаду в байтах). Середовище розроблення SCADA автоматично розраховує адреси зміщення та бітів для інших полів. Якщо в цьому випадку піти класичним шляхом (без використання структурних типів), усі поля були б як окремі змінні, тобто кількість змінних збільшилась би в 11 разів, і для кожної треба б було окремо задавати усі властивості. Це, можливо, було б не так складно, якби таке “набивання” тегів проводилося один раз. Однак на практиці, завжди доводиться редагувати властивості тегів. Подумайте, скільки змін прийдеться робити в проекті, якщо всі адреси зміщуються на один байт! Кількість змін буде більша або рівною кількості змінних (не важливо структурних чи ні).
Цей підхід може бути розвинутий до ще більш потужних механізмів. Наприклад використання об’єктно-орієнтованого програмування може забезпечити супроводження структури кодом обробки. У деяких SCADA/HMI в типі також означується поведінка тегу. Наприклад, у SCADA zenon у типі змінної можна налаштувати межі тривог, кольори відображення при досягненні меж, тексти повідомлень, обмеження на введення і т. п. Наявність наслідування типів також значно спрощує розроблення проекту.
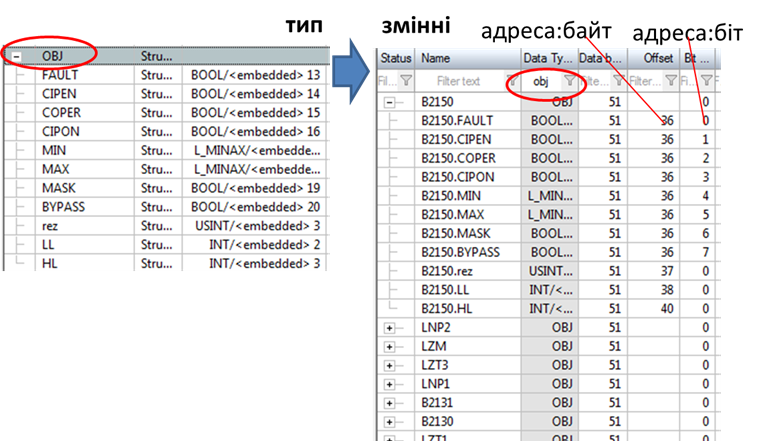
Рис. 8. Структурні типи та змінні в SCADA zenon
Не дивлячись на потужні можливості користувацьких типів, є певні нюанси, які необхідно враховувати при їх використанні. Зокрема, структури в джерелі даних (наприклад контролері) можуть вирівнюватися в пам’яті за одною ознакою, а в джерелі – за іншою. Наприклад, в ПЛК Modicon M340 (Schneider Electric, поля типу BOOL в структурах вирівнюються по байтах (кожне поле BOOL буде займати окремий байт), а в SCADA zenon – по бітах. Тобто в M340 кожне нове поле BOOL буде зміщуватися на один байт, а в SCADA – на один біт. У цьому випадку для того щоб ці структури вирівняти, доведеться в SCADA zenon вводити на кожен BOOL ще по сім порожніх (непотрібних) BOOL або відмовитися від типу BOOL на користь пакування.
9. Деякі підходи до організації БДРЧ
Організації, що розроблюють автоматизовані системи керування, часто користуються певними стандартизованими принципами розроблення прикладного ПЗ або навіть роблять свої програмні каркаси (набір правил та бібліотек для розроблення), наприклад PAC Framework. У цьому параграфі показані деякі типові підходи і прийоми до організації БДРЧ.
9.1. Пакування бітів в теги
Як правило, кожен тег введення/виведення рахується як ліцензована одиниця SCADA/HMI. Іншими словами, чим більше тегів I/O, тим дорожча буде ліцензія на використання середовища виконання SCADA/HMI. Велику частку тегів при цьому займають ті, що мають за джерело змінні типу BOOL. Часто розробники використовують прийом, при якому всі значення змінних з типом BOOL пакують у змінні цілого типу (16-біні INT, UINT, або 32-бітні DINT, UDINT). Тобто в кожен біт цілої змінної записують значення однієї змінної типу BOOL. Таким чином, в упакованому 16-бітному INT можна передати 16 значень BOOL, а в 32-бітному – 32. Неважко зрозуміти, на скільки (навіть у скільки разів) зменшиться кількість тегів БДРЧ.
У ПЛК пакування (і розпакування) запрограмувати досить легко, адже є можливість прямого звернення до біту слова. У SCADA/HMI такої можливості може не бути, однак може бути доступним механізми математичного та логічного оброблення. Яким чином, скажімо, дізнатися в якому стані знаходиться 12-й біт в змінній WPACK типу INT? Є декілька варіантів. Наприклад, можна визначити, чи 12-й біт в 1, використавши порівняння значення складеного по побітовому AND з маскою:
WPACK AND 4096 < > 0
де 4096 – це маска, яка в двійковому форматі має вигляд: 0001_0000_0000_0000. Враховуючи, що всі біти 0-ві, окрім 12-го, побітове AND дасть в усіх бітах 0, окрім хіба що 12-го, який у випадку 1 дасть ненульовий результат. Тобто, якщо 12-й біт буде 1, то результат буде ненульовий, а якщо 0 – то нульовий.
Це показано у випадку читання. Якщо необхідно записати (упакувати) якийсь біт в SCADA/HMI, можна також скористатися операціями з маскою. Щоб записати лог. “1” в 12-й біт, можна виконати таку дію:
WPACK = WPACK OR 4096
А щоб записати логічний 0, треба скористатися маскою у двійковому вигляді 1110_1111_1111_1111 (61439 у десятковому) та побітовим AND:
WPACK = WPACK AND 61439
При такому записі усі біти, окрім 12-го, залишаться в тому ж стані, що й були, а в 12-й запишеться лог.”0”.
При пакуванні слід акуратно користуватися константами, щоб SCADA/HMI система коректно виконала дію. Особливо це стосується пакування 15-го біту в 16-бітному слові, який може відповідати за знак. Так, константа 1110_1111_1111_1111 при інтерпретації 16-бітного INT буде дорівнювати від’ємному числу -4097.
9.2. Використання буферів
Окрім даних реального часу, з кожним об’єктом автоматизації (регулятором, виконавчим механізмом, технологічною змінною) пов’язана велика кількість конфігураційних даних (CFG DATA), які потрібно передавати в/зі SCADA/HMI тільки за необхідністю. Оскільки більшість SCADA/HMI ліцензуються за кількістю точок введення/виведення, для зменшення великої кількості конфігураційних даних, що циркулюють між SCADA/HMI та контролером, пропонується використовувати буфер [1]. Для кожного масиву (набору) однотипних об’єктів рекомендується використовувати свій буфер. Кожен об’єкт має унікальний у межах набору ідентифікатор, за яким можна його зв’язати з буфером (рис. 9). У будь-який момент часу змінні CFG_BUFER (конфігураційний буфер), CMi_HMI…CMj_HMI (структура зі значеннями стану реального часу, де i,,j – умовні ідентифікатори змінних) в SCADA/HMI пов’язані з однойменними змінними в ПЛК. Отримуючи команду на читання (CMD=READ_CFG), відповідний об’єкт (i..j) в ПЛК завантажує свої конфігураційні дані в буфер та пов’язується з ним (займає/оволодіває ним). Під час займання буферу в ньому оновлюються дані реального часу від обраного об’єкта. Це можуть бути не тільки видимі RT DATA, а додаткові відлагоджувальні дані (номер кроку, час кроку, значення інтегралу і т.п.), які немає сенсу відображати постійно. Конфігураційні дані оновлюються в буфері тільки по команді на читання. Це зроблено для того, щоб оператор міг змінити ці значення в буфері і записати їх в об’єкт відповідною командою CMD=WRITE_CFG.
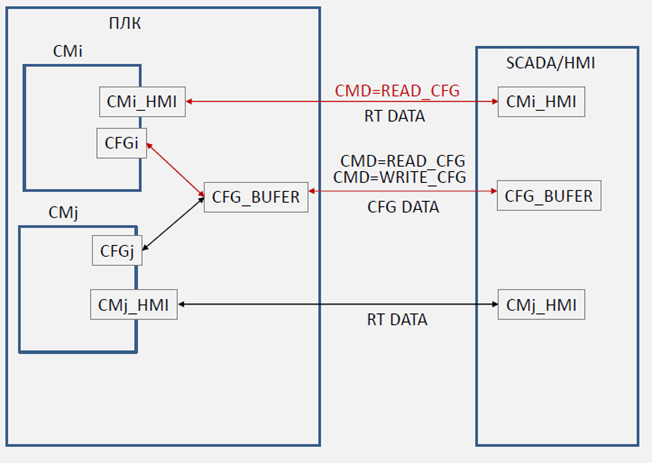
Рис. 9 Приклад конфігурування кранів на HMI.
На рис. 10 наведено приклад, яким чином може використовуватися буфер при налаштуванні аналогових змінних. На HMI постійно відображається значення змінних та їх стан (біти тривог та інші статуси). При виборі необхідної змінної на дисплеї (підсвічується світло-сірим фоном), на ПЛК відправляється команда завантаження даних цієї змінної в буфер. Вміст буфера відображається в правій частині дисплею – це параметри масштабування, фільтрації, меж тривог тощо. Конфігураційні параметри зчитуються тільки в момент вибору змінної або натискання кнопки “Прочитати”. Інші значення, такі як “код АЦП” (немасштабоване значення), “Значення” (масштабоване), оновлюються в буфері постійно. Наладчик може змінити будь-яке конфігураційне значення в буфері, але тільки після команди “Зберегти” воно буде перезаписано з буфера в конфігураційні параметри вибраної змінної в ПЛК. Таким чином, для всіх конфігураційних даних виділяється тільки одна змінна в SCADA/HMI, яка за фактом є буферною.
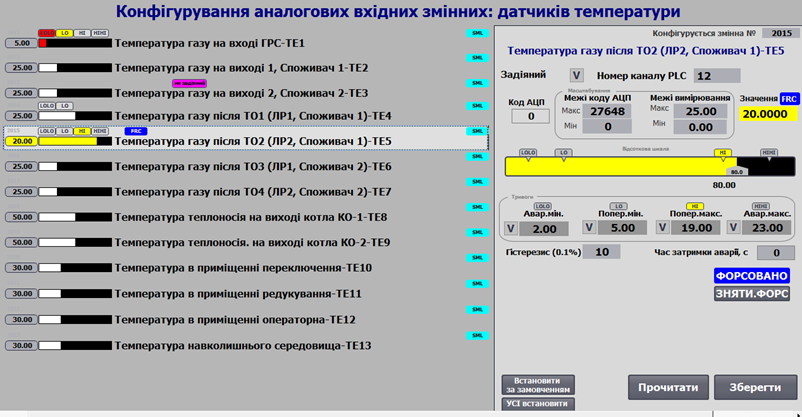
Рис. 10 Приклад використання буферу для налаштування аналогових змінних на HMI
Не дивлячись на значну економію ресурсів, використання буфера супроводжується рядом обмежень. Найбільш суттєвим обмеженням є неможливість використання буфера з 2-х та більше засобів ЛМІ. При одночасному використанні буфер “відбирається” останнім користувачем. Іншим недоліком є відмова від табличних виглядів карт технологічних змінних.
9.3. Використання індексної адресації
Альтернативою буферу може бути індексна адресація, коли в якості адреси даних використовується індекс або зміщення. Наприклад, у WinCC для операторських панелей, що працюють з контролерами Simatic, за індекс можна використовувати номер блока даних (DB). На рис. 11 номер DB задається значенням внутрішнього тегу ObjID. У такому випадку можна при переході до екрана відображення інформації аналогової величини TT101 передавати у тег ObjID значення 101, при цьому тег TTxxx_AH буде пов’язаний з %DB101.DBD36. А при переході до екрану відображення інформації аналогової величини TT203 передавати у тег ObjID значення 203, при цьому тег TTxxx_AH буде пов’язаний з %DB203.DBD36.
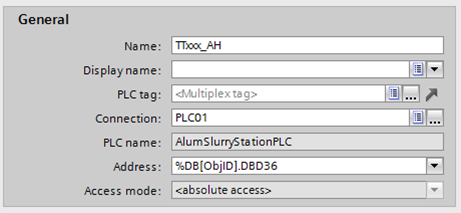
Рис. 11 Приклад конфігурування використання індексу в анімації
10. Підходи до автоматизації створення БДРЧ
Для невеликих проектів SCADA/HMI кожний тег можна конфігурувати самостійно. Однак якщо кількість тегів вимірюється сотнями і тисячами, виникає потреба автоматизувати процес створення записів у конфігураційній базі даних проекту. Слово “автоматизація” тут розуміється саме в контексті розроблення і стосується заповнення та редагування не тільки бази даних тегів, а і інших розділів проектів. Із процедур до “автоматизованого” наповнення та редагування бази даних проекту можна віднести два підходи:
‒ імпортування (import) конфігураційних даних;
‒ зв’язування (linking, “лінкування“) із зовнішньою базою даних.
Імпортування передбачає копіювання конфігураційних даних з бази даних певного формату, їх перетворення в потрібний вигляд та занесення в базу даних проекту SCADA/HMI. При цьому середовище розроблення може підтримувати різні формати файлу. Як правило, це CSV, XML, OPC (з простору імен) або файли проектів ПЛК. Імпортування проводиться тільки за необхідністю, як правило один раз, при створенні записів у базі даних проекту. Це процедура “втягування” вже створених в іншому редакторі даних.
Зв’язування (сленгова назва “лінкування”), на відміну від імпортування тримає зв’язок бази даних проекту з зовнішньою базою. Як правило, усі поля бази даних проекту, які є зв’язаними, не можуть редагуватися, оскільки вони посилаються на зовнішнє джерело. Типовим прикладом зв’язування є підключення бази даних або її частини до файлу проекту ПЛК, в якому зберігається інформація про змінні. Зв’язування є потужним механізмом утримання бази даних тегів проекту інтегрованою для ПЛК та SCADA/HMI. Тобто будь-яка зміна налаштування змінної в ПЛК автоматично (або за запитом оновлення) приводить до зміни в проекті SCADA/HMI. Великі бренди намагаються зводити це зв’язування до максимальної наближеності до єдності тегів SCADA/HMI+ПЛК. Наприклад, в “Simatic PCS” розроблення прикладного ПЗ ініціюється зі SCADA/HMI, і всі теги створюються автоматично і для БДРЧ SCADA і для ПЛК. Аналогічним чином це робиться у “Hybrid DCS” від Schneider Electric.
Імпортування змінних (як і інших розділів проекту) передбачає наявність файлу імпорту в тому форматі, який розуміє даний редактор SCADA/HMI. Якщо імпорт передбачає ручне створення файлу (наприклад в Excel або XML-редакторі), наявність можливості підтримки, наприклад, форматів CSV або XML, ще не каже про те, які саме поля або імена будуть використовуватися в цих файлах. Як варіант, опис структури файлу імпорту можна взяти з довідкової системи інструменту, однак повного переліку полів там може не бути. Виходом з цього, може бути використання зворотної процедури, тобто експорту тегів у файл, який, по суті, стане прототипом необхідного файлу імпорту. Наприклад, SCADA zenon надає можливість імпорту та експорту як в XML так і CSV. Зробивши експорт однієї змінної в CSV (рис. 12), можна файл експорту відкрити в Excel, після чого добавити туди всі необхідні записи, скориставшись автоматизацією Excel (автоматичне збільшення значення по колонці, копіювання/вставка по взірцю і т.п.). Після внесення змін у редакторі запускається процедура імпорту. Якщо змінні збігаються, редактор дає можливість вибрати заміну, зберегти чи відмінити імпорт.
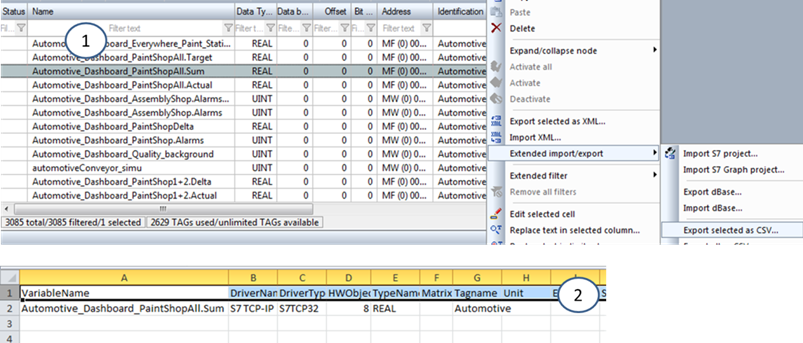
Рис. 12. Приклад експорту змінних в SCADA zenon: 1 – процедура експорту, 2 – вигляд експортованого файлу CSV в Excel
Слід звернути увагу, що згадані вище файли CSV вказують тільки на те, що використовується формат представлення таблиць у вигляді текстових записів, розділених символом переносу рядка, в яких є поля, що розділені розділовим знаком. У якості розділового знаку може бути як кома, так і табуляція, крапка з комою чи інші. Для коректного сприйняття такого файлу редакторами, можна замінити одні розділові знаки на інші в простому текстовому редакторі, наприклад блокноті, шляхом пошуку та заміни. Пара Excel + Notepad (або Notepad++) є дуже корисними помічниками при створенні програмного забезпечення АСКТП.
Застосування механізмів імпорту/експорту дає можливість використати вихідні дані для проекту не тільки для розуміння технічних вимог, а й для пришвидшення процедури розроблення. Тому у фірмах інтеграторах намагаються уніфікувати вихідні дані у вигляді таблиць, де вказана вся необхідна інформація. Так, у табл. 1 показано фрагмент списку введення/виведення для ПЛК, який, у свою чергу, легко перетворюється на таблицю змінних ПЛК<->SCADA, що може бути використана при формуванні файлу імпорту.
Універсальні формати типу CSV чи XML не єдині, що можуть підтримувати середовище розроблення для імпорту змінних. Нерідко SCADA/HMI підтримують можливість імпорту безпосередньо з файлів проектів ПЛК різних виробників. Наприклад, SCADA zenon підтримує імпорт із файлів проектів Step7 (див. рис. 12). Такий імпорт може підтримувати зв’язок з вихідним файлом з можливістю оновлення, у цьому випадку це називають зв’язуванням.
Таблиця 1.
Приклад фрагменту таблиці I/O для ПЛК
| Найменування | Од. вимір. | Познач | Тип | Мод.кан | Діапазон перетворювача | Діапазон вимірювання | Пороги | Номін. | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Мін | Мах | Мін | Мах | А нижнє | П нижнє | П верхнє | А верхнє | ||||||
| Тиск газу на вході ГРС | кгс*см2 | PT1 | AI | 0.0 | 0 | 60 | 0 | 60 | 25 | 55 | |||
| Тиск газу на виході ГРС | кгс*см2 | PT2 | AI | 0.1 | 0 | 16 | 0 | 16 | 20% | 10% | 10% | 20% | 2.0 |
| Тиск газу на власні потреби | кгс*см2 | PT3 | AI | 0.2 | 0 | 0.1 | 0 | 0.1 | 0 | 0.04 | |||
| Тиск теплоносія в системі підігріву газу | кгс*см2 | PT4 | AI | 0.3 | 0 | 10 | 0 | 10 | 3 | 5 | |||
| Тиск газу на вході редукування | кгс*см2 | PT5 | AI | 0.4 | 0 | 16 | 0 | 16 | |||||
| Резерв(5) | AI | 0.5 | |||||||||||
| Резерв(6) | AI | 0.6 |
Зв’язування продемонструємо на SCADA Citect (рис. 13). У цьому випадку зв’язування проводиться з пристроєм введення/виведення (I/O Device). Для деяких типів пристроїв (контролерів) прописані правила зв’язування з файлом проекту. Наприклад, у Citect є правила зв’язування з OPC-тегами OFS (OPC Factory Sever) та проектом EcoStruxure™ Control Expert (раніше відомий як Unity Pro), за допомогою яких можна автоматично будувати теги I/O, та тримати їх зв’язаними з вихідними даними. Це значить, що властивості цих тегів у середовищі розроблення не редагуються, але можуть бути оновлені даними з вихідних файлів, коли вони зміняться. Таким чином, якщо, скажімо, зміняться адреси тегів в ПЛК, при оновленні зв’язування, властивості «Адрес» (див. рис. 13(4)) також автоматично зміняться. Зв’язування дає можливість не дублювати однакові поля тегів у ПЛК та SCADA/HMI і, що ще важливіше, – тримати зв’язок між цими частинами системи завжди узгодженим.
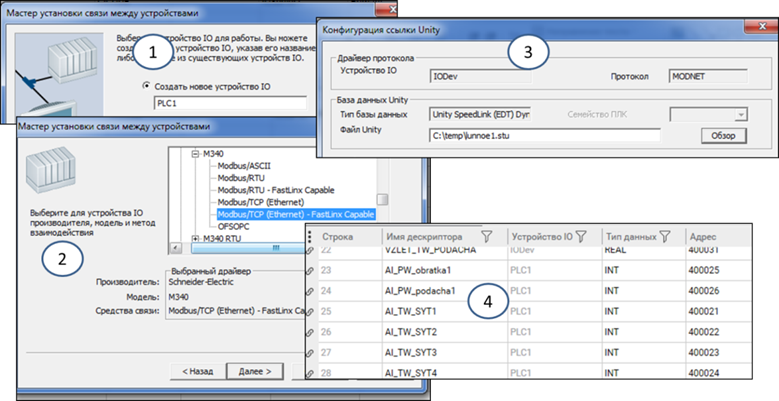
Рис. 13. Приклад зв’язування пристрою I/O при його створенні з файлом проекту EcoStruxure™ Control Expert (раніше відомий як Unity Pro): 1 – запуск майстра і створення ім’я пристрою I/O; 2 – вибір типу драйвера; 3 – вибір зв’язаного проекту; 4 – автоматично створені зв’язані теги введення/виведення
Контрольні запитання
-
Що таке база даних реального часу?
-
Що таке сервер введення/виведення , хто для нього є клієнтами?
-
Яке призначення підсистеми введення/виведення? З якими проблемами може зустрітися розробник при реалізації зв’язку SCADA/HMI з пристроями ?
-
Поясніть, що таке тег (змінна) в SCADA/HMI.
-
Чим відрізняються теги (змінні) введення/виведення від внутрішніх? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які відмінності між серверними та клієнтськими внутрішніми тегами? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які властивості можуть налаштовуватися для тегів введення/виведення ? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Яка обробка може відбуватися для тегів введення/виведення ?
-
Як може формуватися простір імен тегів в SCADA/HMI? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Навіщо потрібна ієрархічність в найменуваннях тегів?
-
Як можна вирішити питання надання ієрархічності в плоскому просторі імен? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Розкажіть про структурування тегів. Покажіть на прикладі однієї з програм SCADA/HMI.
-
Навіщо може бути використаний коментар для тегу? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які необхідні властивості, щоб налаштувати зв’язок з джерелом даних? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Від чого залежить як часто проводиться обмін з джерелом даних? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Навіщо необхідно проводити масштабування для тегів введення/виведення?
-
Розкажіть, як в SCADA/HMI може налаштовуватися масштабування для тегів введення/виведення? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Розкажіть про налаштування масштабування для тегів введення/виведення через використання діапазонів. Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які налаштування проводяться для відображення значення у вигляді тексту? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які властивості характеризують стан тегу в режимі виконання?
-
Розкажіть про властивість недостовірності. Як вона може відображатися на людино-машинному інтерфейсі? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Які властивості тегів режиму виконання можуть знадобитися в SCADA/HMI для контролю і для чого? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Навіщо конфігурувати тип для тегу введення/виведення?
-
Розкажіть про неявне перетворення типів у джерелі і в БДРЧ? Покажіть на прикладі однієї з програм SCADA/HMI.
-
Розкажіть про різне найменування типів в SCADA/HMI і джерелі даних. Покажіть на прикладі однієї з програм SCADA/HMI.
-
Розкажіть про використання користувацьких структурних типів. Які переваги при цьому може отримати розробник?
-
Які особливості треба врахувати при використанні структурних тегів?
-
Розкажіть про механізм упакування бітів у тегах введення/виведення.
-
Розкажіть, як можна визначати стан бітів за маскою та встановлювати потрібний біт.
-
Розкажіть про використання буферного обміну для економії кількості тегів введення/виведення.
-
Розкажіть про використання індексної адресації в анімації.
-
Розкажіть про використання імпортування та лінкування тегів Чим ці механізми відрізняються?
-
Покажіть на прикладі однієї з програм SCADA/HMI, як можна зробити імпорт тегів з зовнішнього файлу CSV або XML.
-
Покажіть на прикладі однієї з програм SCADA/HMI, як можна зробити імпорт та зв’язування тегів з проекту для ПЛК.
-
Покажіть на прикладі однієї з програм SCADA/HMI, як задається масив для тегів введення/виведення.
Список використаних джерел
- PAC Framework V1.02. Функціональний каркас для розроблення прикладного програмного забезпечення для промислових контролерів [Електронний ресурс]. Доступно: https://github.com/pupenasan/PACFramework
Теоретичне заняття розробив Олександр Пупена.